笔者在高中的时候就有这样的想法,既然平时阅卷都是电脑阅卷,答题卡都已经扫描进了系统,那么能不能利用OCR技术来提取答题卡上面的答案,然后再将它输入到处理过题目(参考过出卷人给出标准答案)的大语言模型中,最后通过大语言模型的理解来给出较为客观的分数呢?
本次先讨论该过程的第一项,利用OCR技术来识别字迹。
手写识别
首先我们要先解决如何将答题卡中的手写字迹给识别成我们屏幕上显示出来的字符,以便输入给大语言模型进行处理。事实上由于每个人的书写习惯存在很大区别,中文字体的随机性很大,比如连笔,草书等,手写识别的难度其实很大。笔者在网上找到了大致有两种手写识别的解决方案,一种是商用的,而另外一种是GitHub的开源项目,我们分别来进行测试来比较两者的准确度。
值得注意的是,本次用来提供测试的题目为物理实验填空题,答案较为唯一,但是涉及一些科学符号,因此识别的难度可能较高,样本的总数为10份。
本次商业的手写文字识别我们选用了百度和有道云。
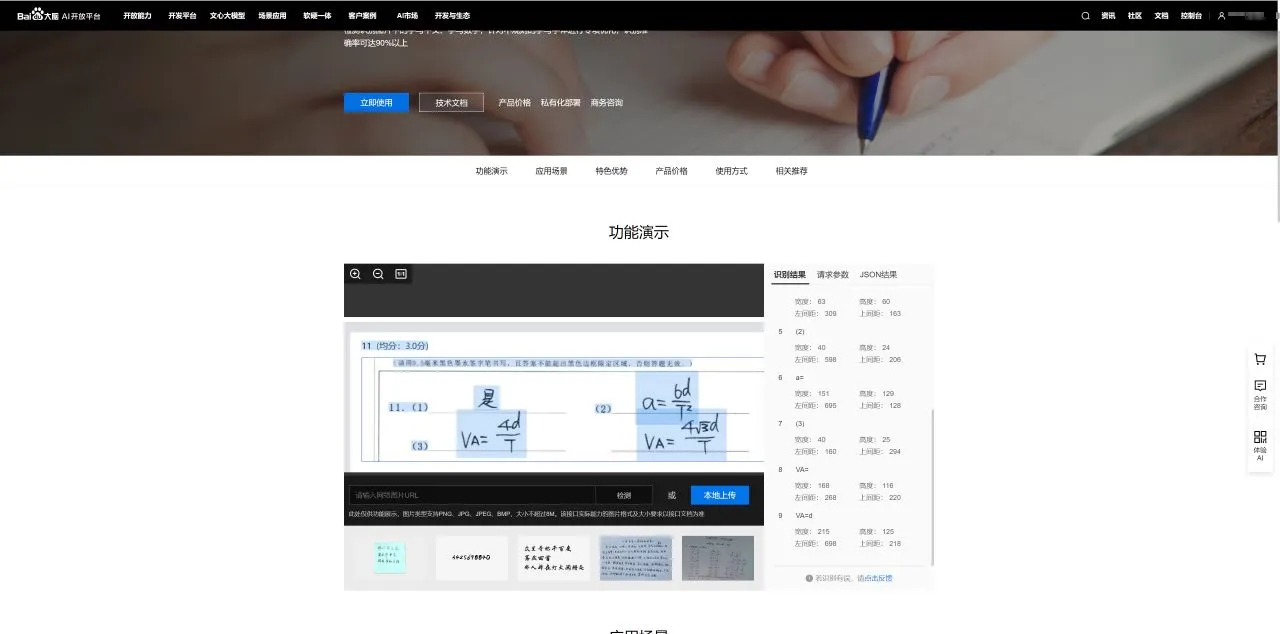
首先出场是是百度,当我上传图片的时候发现了很诡异的事情,似乎百度并没有针对手写数学符号场景进行优化,原本的数学符号硬生生被识别成了各种各样的数字

我之后又多尝试了几份试卷,结果都类似,百度的手写识别只能处理最基本的文字,而对于符号只能识别诸如等号这种最基础的数学符号
甚至对于这种字迹比较潦草的,它甚至放弃识别,只能识别到较为清晰的部分
接下来我们继续尝试有道云,和百度的情况类似,还是无法正常地识别到其中的符号,他们更倾向于将其识别为汉字而不是数学符号

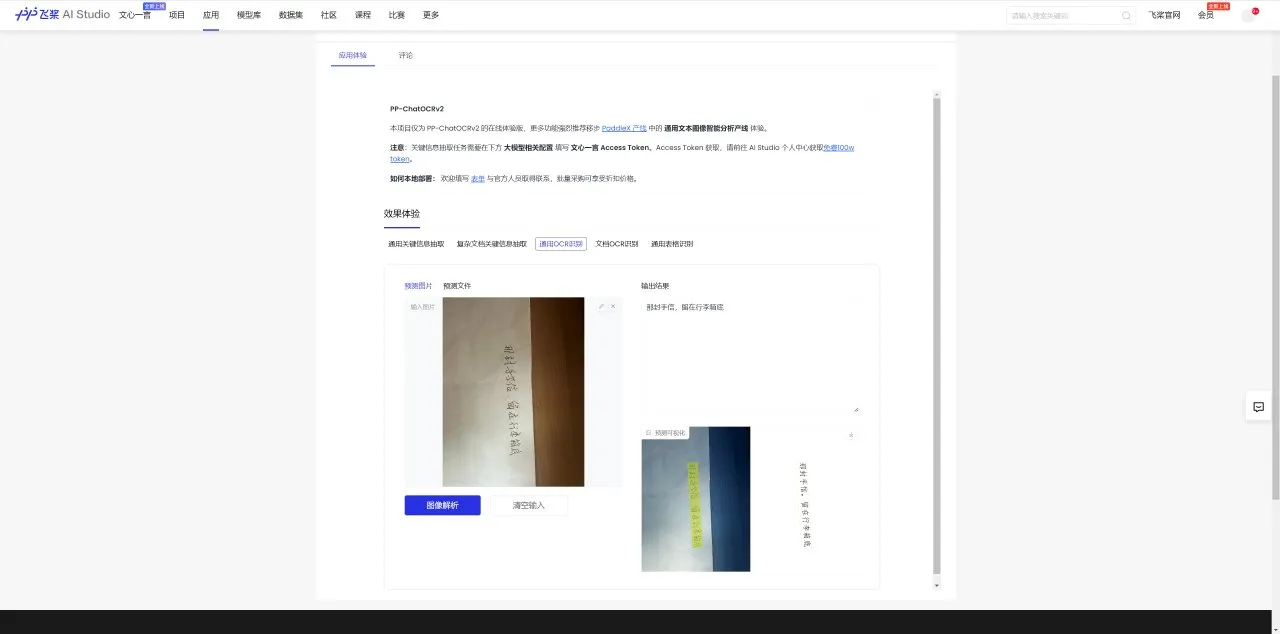
然后是开源项目,我选用了PaddleOCR,这个项目在GitHub上已经斩获了36.4K的Stars,而我这次试用的是其中的PP-ChatOCRv2在线体验,在这里我们使用通用OCR识别
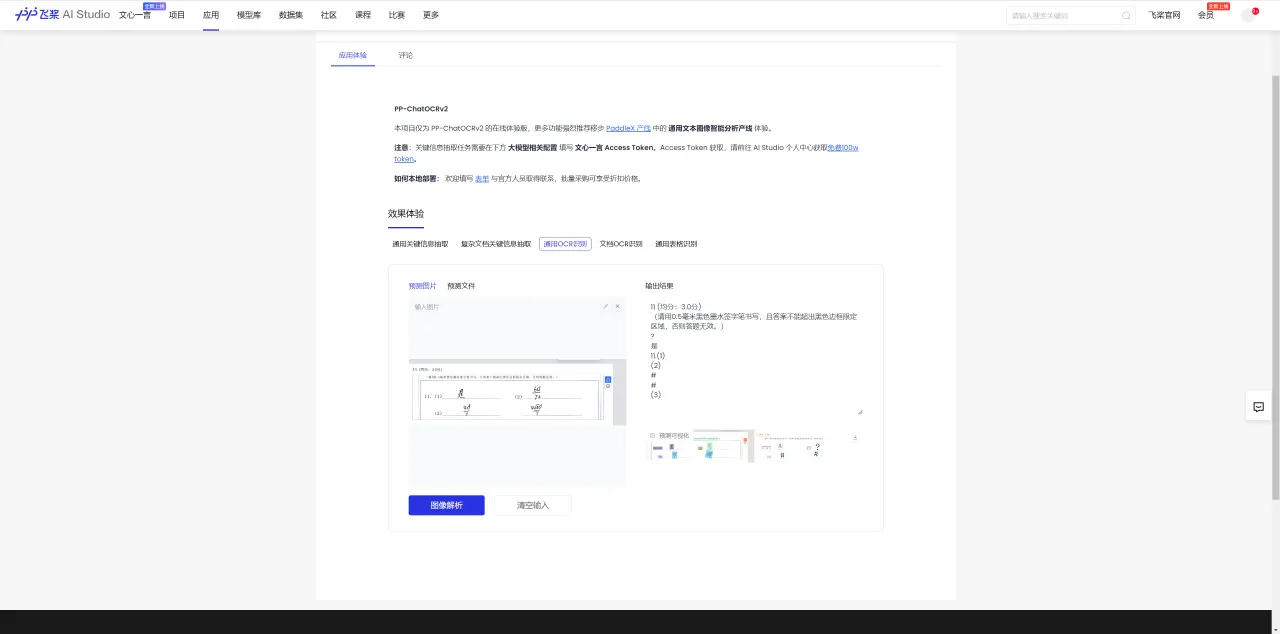
可以看到还是无法正常识别数学符号
题外
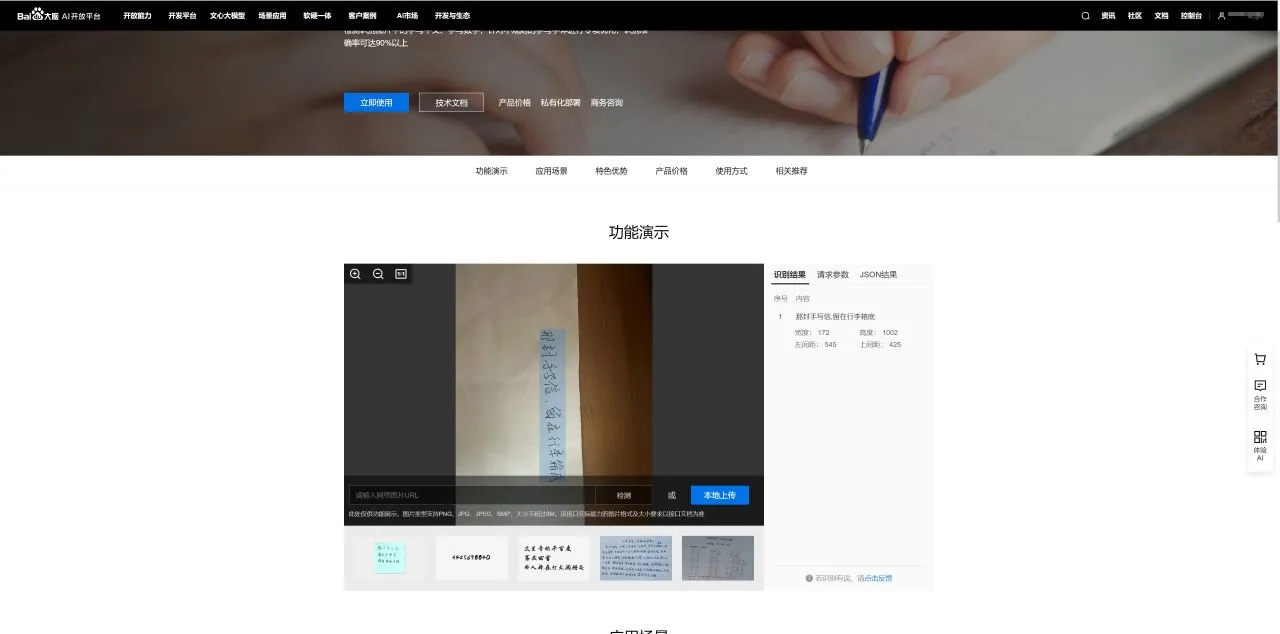
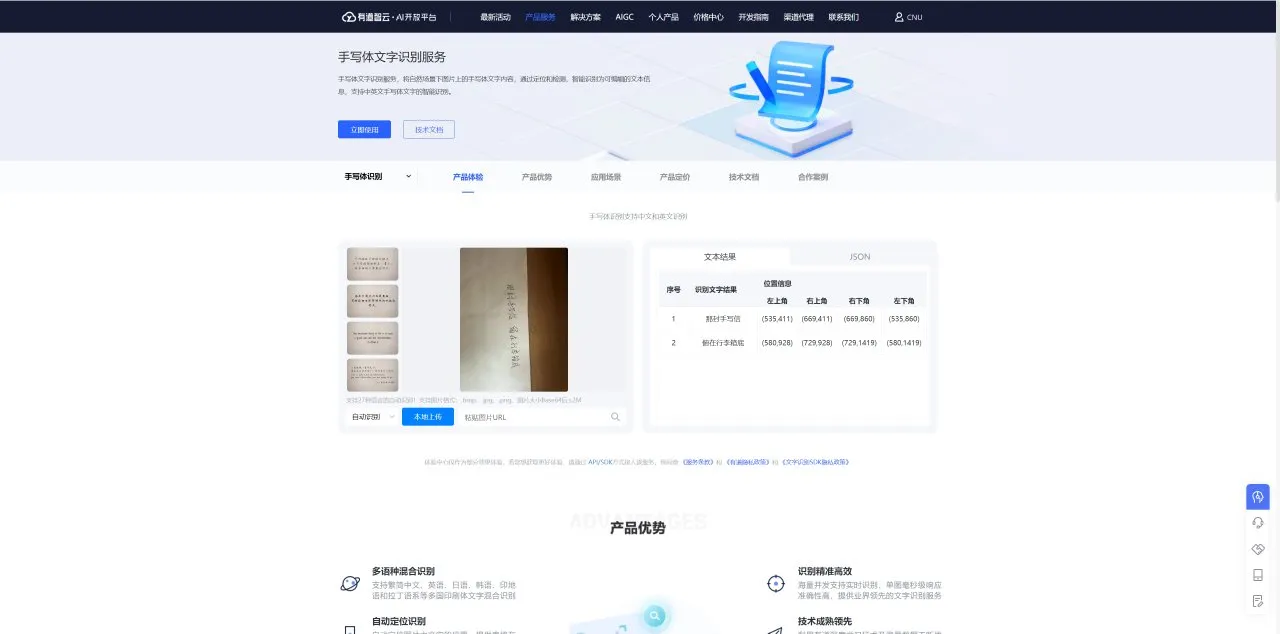
实际上,笔者在测试数学符号识别的同时还测试了书写文字的识别,原图是这样的

实际上无论是开源模型或者是商用的,对于这种纯文本的识别率还是很高的,其中百度的全部识别正确,有道云将其中的留识别成了俯,而开源模型则没有识别出中间的写字。
综述
从以上结果来看,目前的OCR手写识别对于纯文本的支持还是较好的,但是对于数学符号的识别较差,识别率较低甚至无法识别。在未来,是不是要训练出一些特殊的模型针对这一情况继续优化从而提高数学符号的识别率。
OCR文字识别是利用现代人工智能来提高教育质量的很重要的一步,希望在未来人工智能能更好地赋能教育,少一些人工智能花里胡哨的骗局,多一些实在的技术落地,促进教育平等,提升教育质量。