
北京时间2024年2月16日凌晨,OpenAI发X推出自己最新的大模型Sora,能够根据文字指令创造出既逼真又充满想象力的场景,而且生成长达1分钟的超长视频,还是一镜到底那种。
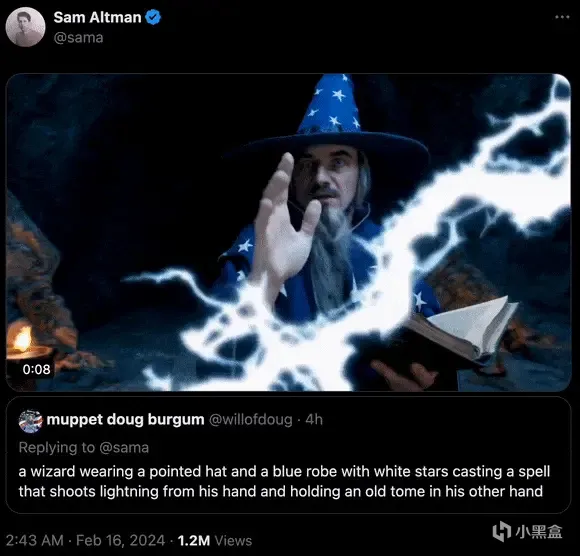
一位戴着尖顶帽,身披绣有白色星星的蓝色长袍的巫师正在施法,他的一只手射出闪电,另一只手中拿着一本旧书。
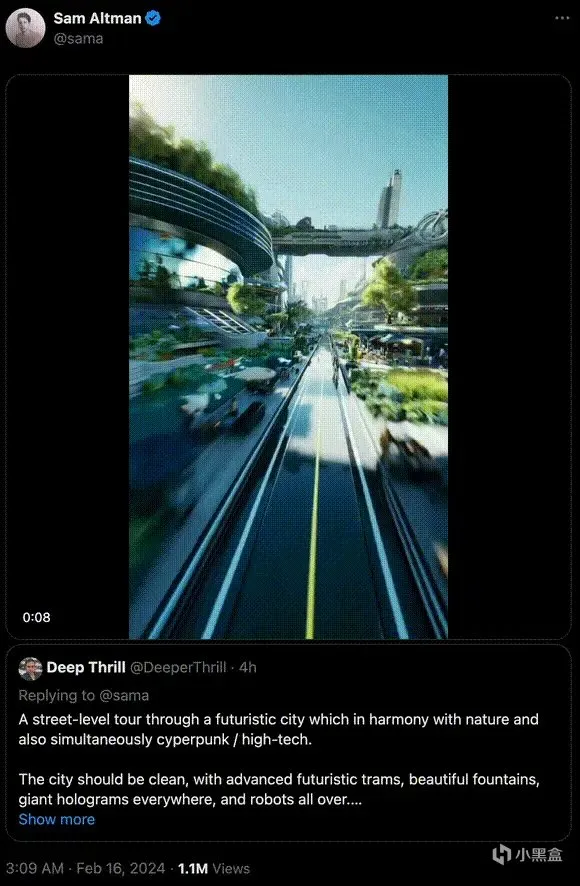
我们将带你进行一次未来城市的街头巡览,在这里,高科技与自然和谐共处,展现出一种独特的赛博朋克风格。
这座城市洁净无瑕,到处可见的是先进的未来式有轨电车、绚丽的喷泉、巨型的全息投影以及四处巡逻的机器人。
想象一下,一个来自未来的人类导游正带领—群好奇的外星访客,向他们展示人类极致创造力的结晶——这座无与伦比、充满魅力的未来城市。
上面是文本描述生成的视频演示,由OpenAI的CEO亲自发X来展示。
下面是OpenAI官网展示的视频
OpenAI官网-sora大模型

Prompt:
“A stylish woman walks down a Tokyo street filled with warm glowing neon and animated city signage. she wears a black leather jacket, a long red dress, and black boots, and carries a black purse. she wears sunglasses and red lipstick. she walks confidently and casually. the street is damp and reflective, creating a mirror effect of the colorful lights. many pedestrians walk about.”
中文指令:
“一位时尚女性走在充满温暖霓虹灯和动画城市标牌的东京街道上。她穿着黑色皮夹克、红色长裙和黑色靴子,拎着黑色钱包。她戴着太阳镜,涂着红色口红。她走路自信而随意。街道潮湿且反光,在彩色灯光的照射下形成镜面效果。很多行人走来走去。”
OpenAI 官方文档介绍:Sora是一种扩散模型,主要通过静态噪音的视频开始生成视频,然后再通过多个步骤去除噪音,逐渐转换视频。
Sora 与 ChatGPT 一样采用 Transformer 架构,并使用了 DALL-E 3 中的重述技术,是一种为视觉训练数据生成高精准描述性的字幕。
所以,Sora 在生成视频过程中精准还原用户的文本提示语义。
除了文本生成视频之外,Sora 还能根据图像生成视频,并能准确地对图像内容进行动画处理。也能提取视频中的元素,对其进行扩展或填充缺失的帧,功能非常全面。